
Blog
How replicable is innovation research?
Hollie Lippert, Josh Eyre, Purba Sarkar, Maria Agostina Beveraggi Vidal, Nadia Atala-Proano
29 November 2018
Evidence-based policy is only as good as the quality of the evidence it is based on. But is most evidence of high quality? And what (and whom) even measures the quality of evidence?
In recent years, the ability to successfully replicate or reproduce findings has been gaining steam as one straight-forward measure of high quality evidence. The rise of this measure has also highlighted what some are terming a replication crisis in scientific research – researchers are findings that much evidence cannot in fact be successfully reproduced, leading to the loss of confidence in evidence and research quality. Replication is not all crisis and poor evidence – replicating and updating findings are also core mechanisms for scientific advancement. In this context, replications are an invaluable tool to validate and improve evidence before resources are committed to policy development and implementation.
IGL teamed up with a team of LSE Masters students on a project aimed to explore replicability and the use of replications within the innovation, entrepreneurship and growth (IEG) research field. The project consisted of performing an analysis of data availability and replicability of studies contained within the IGL online database, and then conducting interviews with researchers and other stakeholders regarding the topic. The remainder of this blog will present the core findings from this project.
First, what is a replication?
Replication is an incredibly broad term with many nuanced meanings in scientific research. In the narrowest sense, replication refers to using the exact same data and code as an original research study to ensure the accuracy of the original evidence presented. In a wider sense, replications may also refer to various forms of robustness checks or extensions of research—analysing the data using different methodology specifications, collecting new data, or running the same experiment again but in a different setting.
Whether narrow and wide, or something in between, replications are useful, and both definitions of the term are accurate. What is important to note, however, is that most facets of a replication will vary significantly depending on the definition utilised – the purpose, the actual actions associated with performing the replication, and the standards for and interpretation of the results. In the study presented in this blog, replications and replicability were primarily approached using the narrowest definition.
What did we do?
We started with the IGL database of 74 papers and dropped the studies that were not yet complete or were not RCTs from our analysis, leaving 57. We checked for data and code online for the remaining papers, and when we couldn’t find it we contacted the authors to request the data. After further contact, we had 22 sets of data and code and were ready to begin the replications. It’s important to note here that data and code availability was one of the major barriers we faced in our research. Without data and code, it is impossible to conduct a replication, but we will talk about this a little further on. To supplement the insight from these replications, we also conducted interviews with researchers, journal editors, and other research stakeholders to understand their views on replications and the barriers to data sharing and replications.
What did we find?
While 22 papers had data and code published alongside them, on closer inspection, eight presented incomplete materials, leaving 14 for us to replicate. Most of the papers replicated were classified as comparable (36%) or partial replications (43%), and overall 13 out of 14 studies were replicable to some degree.
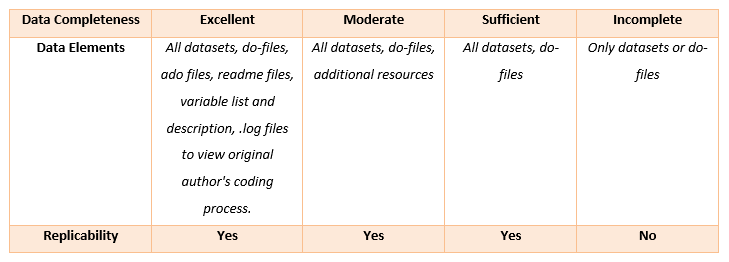
Table 1: Categorisation of data completeness
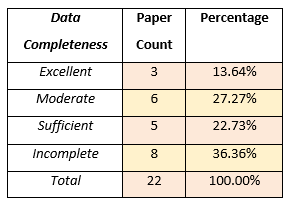
Table 2: Data completeness and paper count in the IGL database
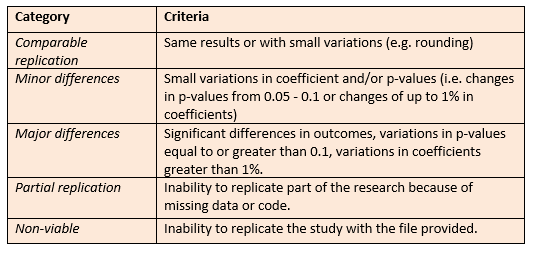
Table 3: Categorisation of replicability (adapted from 3IE, 2017)

Figure 1: Replicability of the IGL database
What is causing this?
Data and code sharing and replications are not as widespread as their advocates are calling for. There are few incentives for researchers to conduct replications or publish their data and code. Researchers are mainly incentivised to conduct original research over replications, as this is what journals publish, and their professional advancement depends on their number of publications. Researchers may not want to publish their data alongside research because they intend to use it for further analysis; publishing it may allow a competitor to get in there first.
Reinforcing the lack of professional pressure in favour of data sharing and replications, is the dearth of social pressure. While our research shows an increasing trend of data sharing and replications, it’s still not the norm among researchers. If you don’t have to do it and none of your peers are, why would you spend the time necessary to clean up data and code to share publicly? Data confidentiality was cited as a big issue from researchers’ perspectives too, with several mentioning that they use commercially sensitive data in their analyses on the condition that it won’t be made public.
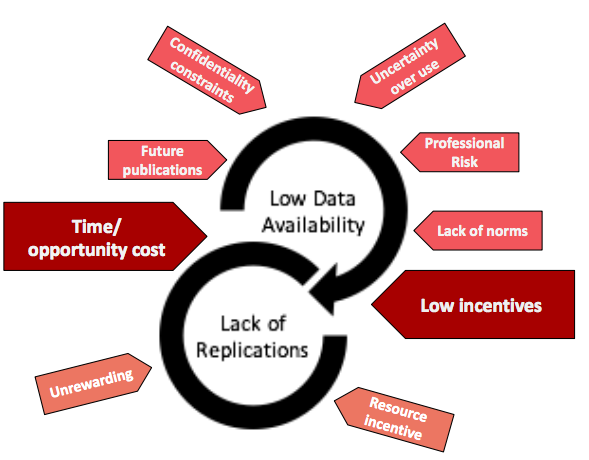
Figure 2: Barriers to data availability, replications and both
What’s to be done?
Journals can play a crucial role in encouraging replications. Many journals, such as the American Economic Review and the American Economic Journal have policies making data and code sharing mandatory before research is published. Unfortunately, these policies are rarely enforced. Enforcing them would incentivise researchers to publish their supporting materials because their career advancement would depend on it.
Academic institutions and research funders could make replications and data sharing compulsory, providing resources – financial, technical, or in terms of manpower – to help researchers overcome time barriers. Replications could be carried out by graduate students as part of their academic programme, with extra credits awarded.
Policymakers could incentivise replication by prioritising evidence from replicated research findings, verifying it before designing policy around it. Third party institutions – organisations like J-PAL, IPA and IGL can offer support to researchers to prepare their data and code for sharing, and advocate for greater replicability, celebrating the journals who stick to their policies and calling out those who don’t.